Introduction
Modern software delivery demands more than just writing functional code. Systems must be resilient, scalable, and highly available under intense production pressure. The Certified Site Reliability Engineer program bridges the gap between traditional software development and infrastructure operations. This comprehensive guide is designed for engineering professionals and technology leaders who want to navigate the complexities of modern platform stability. Within the broader context of DevOps, cloud-native architectures, and modern engineering platforms, establishing a standard for operational reliability has become a strict business requirement. This guide provides a clear, experience-driven analysis to help you make informed decisions about your professional development and career trajectory. For those expanding their expertise into automated operations, resources like aiopsschool offer parallel pathways to mastering intelligent systems.
What is the Certified Site Reliability Engineer?
The Certified Site Reliability Engineer designation is a professional framework that validates an engineer’s ability to apply software engineering mindsets directly to infrastructure and operations problems. Instead of relying on manual intervention and traditional firefighting techniques, this program emphasizes automation, systemic engineering, and architectural resilience. The core philosophy centers on treating operations as a software problem, which aligns perfectly with modern cloud-native enterprise workflows. Rather than focusing purely on theoretical concepts or single-vendor tools, the certification focuses on real-world production engineering, distributed systems management, and structural fault tolerance. It establishes a standardized operating language for managing large-scale infrastructure, ensuring that engineering teams can balance rapid feature deployment with strict system stability and predictable performance metrics.
Who Should Pursue Certified Site Reliability Engineer?
This certification is designed for a wide spectrum of technology professionals who are responsible for the availability and performance of production systems. Systems administrators, DevOps engineers, and cloud architects looking to transition into formal reliability roles will find immediate value in this curriculum. Software developers aiming to understand runtime environments, system bottlenecks, and distributed architecture paradigms will gain deep operational insights. Furthermore, technical managers, infrastructure leads, and engineering directors can leverage this knowledge to build, structure, and scale effective reliability teams within their organizations. The framework holds immense relevance across both global enterprises and the fast-paced technology ecosystem in India, where digital platforms must scale efficiently to support massive consumer bases.
Why Certified Site Reliability Engineer
In an era defined by continuous deployment and hyper-scale cloud environments, the demand for dedicated reliability professionals continues to outpace the available talent pool. Technologies, frameworks, and specific cloud tools shift rapidly, but the fundamental principles of reliability engineering—such as error budgets, telemetry, and distributed system design—remain constant. This certification provides engineers with a foundational, tool-agnostic skill set that preserves its value despite changing industry trends. By investing time into mastering these core competencies, professionals secure a strong return on their career investment, making themselves highly competitive for senior architecture and platform engineering roles. Enterprises actively seek certified individuals to minimize costly downtime, optimize cloud spend, and maintain strict service-level commitments for their global user bases.
Certified Site Reliability Engineer Certification Overview
The formal certification program is delivered through specialized training structures and is officially hosted on the sreschool platform. The assessment approach avoids simple rote memorization, choosing instead to focus on practical scenarios, architectural problem-solving, and operational decision-making. The structure is built to accommodate different professional career stages, offering a logical progression from foundational concepts to advanced, enterprise-scale reliability strategies. The program design maintains complete ownership over the core curriculum, ensuring that the training materials stay current with evolving industry standards and real-world production requirements. By focusing on hands-on competence and analytical thinking, the certification ensures that successful candidates can immediately contribute to live production environments.
Certified Site Reliability Engineer Certification Tracks & Levels
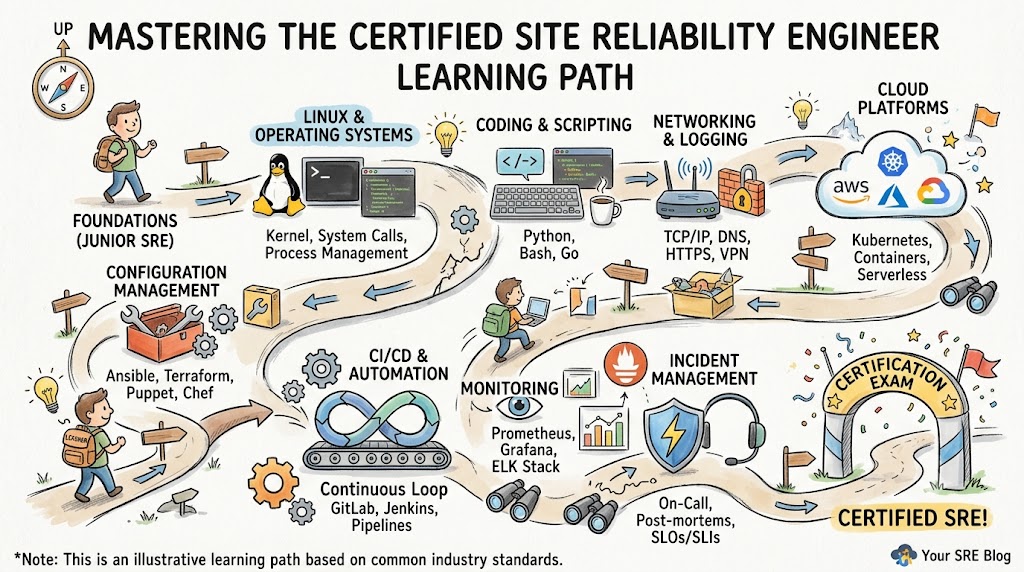
The certification structure is divided into distinct, progressive tiers to match the evolving experience levels of IT professionals. The foundation level introduces core philosophies, basic metrics, and fundamental automation concepts suitable for those entering the domain. The professional level deepens this knowledge by focusing on advanced telemetry, incident response management, and complex distributed system architecture. Finally, the advanced level addresses enterprise-scale governance, chaos engineering strategies, and organizational reliability culture. Specialized tracks allow engineers to align their learning path with specific functional domains, such as integrating reliability with traditional DevOps, securing cloud data pipelines, or optimizing infrastructure cost frameworks across global organizations.
Complete Certified Site Reliability Engineer Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| SRE Core | Foundation | Associate Engineers & SysAdmins | Basic Linux & Networking | SLOs, SLIs, Basic Automation, Postmortems | 1 |
| SRE Core | Professional | Senior DevOps & Cloud Engineers | 2+ Years Cloud Experience | Telemetry, Advanced Incident Response, CI/CD | 2 |
| SRE Core | Advanced | Principal Engineers & Architects | Professional Level SRE | Chaos Engineering, Scale Architecture, Culture | 3 |
| Platform | Specialist | Platform & Infrastructure Teams | Foundation Level SRE | Infrastructure as Code, Kubernetes, GitOps | 4 |
Detailed Guide for Each Certified Site Reliability Engineer Certification
Certified Site Reliability Engineer – Foundation Level
What it is
This certification validates a candidate’s core understanding of basic reliability engineering concepts, terminologies, and fundamental operational metrics. It ensures the engineer understands how to shift from reactive firefighting to proactive, automated system management.
Who should take it
Systems administrators, junior DevOps engineers, and software developers who want to learn the foundational principles of production stability and automated operations.
Skills you’ll gain
- Defining Service Level Indicators (SLIs) and Service Level Objectives (SLOs)
- Implementing basic infrastructure automation scripts
- Conducting blameless postmortems after system outages
- Understanding error budgets and deployment velocities
Real-world projects you should be able to do
- Configure basic monitoring alerts for a web application stack
- Document a comprehensive, blameless postmortem for a simulated production failure
Preparation plan
- 7-14 Days: Review the official study guides, memorize core terminologies, and understand the differences between SLIs, SLOs, and SLAs.
- 30 Days: Participate in standard practical labs, configure basic alerting mechanisms, and study real-world case studies of system failures.
- 60 Days: Deeply analyze sample scenarios, review mock exam questions, and practice writing automation scripts for routine operational tasks.
Common mistakes
- Confusing SLAs with internal operational SLOs
- Focusing entirely on tools rather than learning the core philosophies of reliability engineering
Best next certification after this
- Same-track option: Certified Site Reliability Engineer – Professional Level
- Cross-track option: Cloud Infrastructure Specialist
- Leadership option: Technical Team Lead Foundation
Certified Site Reliability Engineer – Professional Level
What it is
This certification validates advanced competencies in managing complex distributed systems, orchestrating large-scale telemetry networks, and leading incident response operations. It proves an engineer’s ability to maintain high availability across multi-cloud deployments.
Who should take it
Mid-to-senior level engineers, DevOps practitioners, and platform specialists responsible for maintaining live, enterprise-scale production environments.
Skills you’ll gain
- Designing distributed tracing and advanced observability pipelines
- Orchestrating complex incident response frameworks and mitigation strategies
- Automating infrastructure scaling and self-healing systems
- Managing microservices architecture patterns at scale
Real-world projects you should be able to do
- Deploy an integrated Prometheus, Grafana, and OpenTelemetry monitoring matrix across a Kubernetes cluster
- Build an automated self-healing script that mitigates specific database connection drops without human intervention
Preparation plan
- 7-14 Days: Audit your current production knowledge against the advanced exam syllabus and identify gaps in distributed systems theory.
- 30 Days: Build and tear down complex laboratory environments using containers, service meshes, and distributed logging pipelines.
- 60 Days: Conduct simulated failure drills, optimize system performance bottlenecks in test benches, and review advanced scenario-based questions.
Common mistakes
- Underestimating the depth of distributed systems architecture questions
- Neglecting the human and organizational process components of incident response management
Best next certification after this
- Same-track option: Certified Site Reliability Engineer – Advanced Level
- Cross-track option: Advanced Cloud Security Engineer
- Leadership option: SRE Manager / Director of Platform Engineering
Choose Your Learning Path
DevOps Path
The DevOps learning path focuses on the seamless integration of continuous delivery pipelines and operational stability. Engineers moving along this trajectory learn how to inject reliability checks directly into the continuous integration and deployment phases. This minimizes the risk of bad code reaches production environments and streamlines automated rollbacks when anomalies are detected. The focus remains on shared organizational ownership, robust configuration management, and reducing frictional drag between development and operations teams.
DevSecOps Path
Security cannot be treated as an afterthought in high-velocity production systems, which is why this path merges security protocols directly into reliability workflows. Professionals learning this track focus on automated security compliance, continuous vulnerability scanning within infrastructure pipelines, and IAM policy enforcement at scale. By treating security vulnerabilities as standard operational defects, engineers ensure that systems remain both reliable and well-defended against modern threat vectors.
SRE Path
The pure SRE pathway focuses deeply on systems engineering, architectural design patterns, and systemic scale challenges. Candidates explore advanced debugging methodologies, deep kernel tuning, network protocol optimization, and complex storage engine behaviors. This specialized path is tailored for professionals who want to dedicate their careers to building hyper-scale, fault-tolerant platforms that run with minimal human operational intervention.
AIOps Path
As environments grow too large for manual oversight, the AIOps path teaches engineers how to apply machine learning models to infrastructure data. This path covers automated root-cause analysis, predictive anomaly detection, and intelligent alert deduplication across massive data sets. Candidates learn how to transition from traditional threshold-based alerting to dynamic, machine-driven insights that catch system failures before they impact end-users.
MLOps Path
The MLOps path bridges the unique gap between traditional software systems and modern machine learning deployment pipelines. Engineers on this track learn how to manage data versioning, monitor model performance drift in production, and build reliable pipeline architectures for continuous model training. The core goal is ensuring that complex AI workloads run with the same high availability and predictable performance expectations as standard enterprise software applications.
DataOps Path
Data pipelines require distinct reliability metrics, and the DataOps pathway focuses entirely on the integrity, latency, and availability of enterprise data systems. Professionals study how to monitor distributed databases, orchestrate complex ETL pipelines, and manage large-scale data lakes with minimal downtime. This path ensures that analytical engines and real-world data systems receive accurate information without processing delays or synchronization breakdowns.
FinOps Path
Operating at scale requires deep visibility into cloud infrastructure expenditures, which is the exact focus of the FinOps path. Engineers learn how to correlate system performance metrics with actual financial spend, optimizing resource allocation without degrading application reliability. This track covers automated resource decommissioning, cost-aware architecture designs, and real-time cloud budget forecasting across multi-cloud enterprise deployments.
Role → Recommended Certified Site Reliability Engineer Certifications
| Role | Recommended Certifications |
| DevOps Engineer | SRE Foundation, SRE Professional, CI/CD Specialist |
| SRE | SRE Foundation, SRE Professional, SRE Advanced |
| Platform Engineer | SRE Foundation, SRE Professional, GitOps Specialist |
| Cloud Engineer | SRE Foundation, Cloud Architecture Professional |
| Security Engineer | SRE Foundation, DevSecOps Professional |
| Data Engineer | SRE Foundation, DataOps Specialist |
| FinOps Practitioner | SRE Foundation, FinOps Architecture Specialist |
| Engineering Manager | SRE Foundation, SRE Advanced Leadership |
Next Certifications to Take After Certified Site Reliability Engineer
Same Track Progression
After establishing a strong foundation, engineers should focus on deep specialization within the reliability domain. This involves moving directly toward advanced certifications that validate your mastery over chaos engineering practices, large-scale systems architecture, and distributed platform design. Pursuing these higher-tier designations confirms your capacity to architect multi-region systems capable of automatically surviving catastrophic infrastructure losses.
Cross-Track Expansion
Broadening your technical horizons prevents specialization silos and increases your value across interdisciplinary enterprise teams. Once certified in reliability, it is highly effective to pursue specialist qualifications in cloud-native security, automated data engineering, or machine learning infrastructure pipelines. This cross-training allows you to act as a vital bridge between distinct engineering divisions, resolving complex architectural problems that touch multiple platforms.
Leadership & Management Track
For senior engineers looking to step away from daily command-line tasks, transitioning into organizational leadership requires distinct validation. Focus on certifications that emphasize team building, financial budget alignment, incident postmortem governance, and strategic platform engineering roadmap design. This educational path prepares you to build, mentor, and scale dedicated reliability divisions that map technical performance directly to business revenue goals.
Training & Certification Support Providers for Certified Site Reliability Engineer
DevOpsSchool provides extensive, instructor-led training frameworks designed to help working professionals master the core execution policies of modern DevOps and reliability platforms. Their structured courses emphasize practical laboratory environments and real-world infrastructure scenarios.
Cotocus delivers specialized corporate training programs and technical bootcamps focusing on cloud-native automation, configuration management frameworks, and enterprise scaling operations. Their curriculum targets real-world production readiness.
Scmgalaxy offers an extensive repository of technical tutorials, community forums, and learning blueprints focused heavily on source code management, continuous integration systems, and build automation processes.
BestDevOps focuses on delivering highly curated educational content, practical guides, and examination preparation paths for modern infrastructure methodologies and platform engineering frameworks.
devsecopsschool specializes in providing deep-dive security integration courses, helping automated engineering teams build secure pipelines and maintain continuous compliance across cloud infrastructures.
sreschool stands as a premier dedicated learning matrix for reliability engineering, providing comprehensive courseware, labs, and certification paths focused entirely on production uptime and systems stability.
aiopsschool leads educational programs targeting the intersection of artificial intelligence and operations, training engineers to build predictive alerting frameworks and automated data analysis engines.
dataopsschool focuses on delivering specialized training for data pipeline stability, covering the tools and orchestration methods needed to maintain reliable enterprise data infrastructure networks.
finopsschool provides structured educational models focused on cloud financial management, teaching technology teams how to scale infrastructure efficiently while maintaining clear cost accountability.
Frequently Asked Questions (General)
- What is the primary difference between a DevOps engineer and a Site Reliability Engineer?DevOps focuses broadly on the entire software delivery lifecycle, culture, and continuous deployment pipeline velocity. SRE applies specific software engineering disciplines directly to infrastructure operations, focusing heavily on system reliability, automation, and uptime metrics.
- How much coding knowledge is required to successfully pass the SRE certifications?A solid understanding of scripting languages like Python, Go, or Bash is essential, as the core philosophy relies on automating manual tasks. Candidates do not need to be advanced software developers, but they must be comfortable writing automation scripts.
- Are there any formal prerequisites before taking the foundation level exam?There are no rigid formal prerequisites for the foundation level, though a basic understanding of Linux systems administration, cloud architecture, and networking principles is highly recommended.
- How long does it typically take to prepare for the professional level certification?For an engineer with prior cloud and operational experience, dedicated preparation usually spans between thirty to sixty days of consistent study and practical laboratory work.
- Can this certification help an experienced systems administrator transition into cloud roles?Yes, it provides a clear roadmap for traditional infrastructure administrators to modernize their skill sets by adopting software-driven automation and cloud-native architectural patterns.
- What value do error budgets bring to a software engineering team?Error budgets define the acceptable level of system instability, allowing teams to balance rapid feature deployment with the strict operational stability requirements of the business.
- Is the examination format based entirely on multiple-choice questions?The exam formats utilize a combination of multiple-choice questions and complex, scenario-based problem analyses to accurately evaluate an engineer’s real-world troubleshooting capabilities.
- How long does the certification designation remain valid before requiring renewal?The certification credentials remain valid for a period of three years, after which professionals can recertify by passing higher-tier exams or documenting continuing education credits.
- Does the curriculum focus heavily on one specific cloud vendor like AWS or Azure?No, the program is built on tool-agnostic architectural philosophies, ensuring that the skills learned apply universally across AWS, Azure, Google Cloud, or on-premises infrastructure environments.
- Why are blameless postmortems emphasized so heavily in the reliability framework?Blameless postmortems focus on identifying systemic process and architectural failures rather than pointing fingers at individual human errors, which fosters a healthy, engineering-first culture.
- What roles do service level objectives play in everyday business decisions?They serve as the single source of truth for determining whether engineering teams should focus on delivering new features or pivot to stabilizing existing infrastructure assets.
- Is this certification recognized by global technology companies and enterprises?Yes, enterprises worldwide utilize these standardized frameworks to evaluate candidates for senior platform infrastructure, operations management, and reliability roles.
FAQs on Certified Site Reliability Engineer
- How hard is the Certified Site Reliability Engineer examination process compared to other industry tracks?The assessment ranks as moderate to challenging due to its focus on operational scenarios rather than simple definition memorization. Candidates must understand how different components interact under production stress, which requires genuine analytical thinking and a clear grasp of distributed system dynamics.
- Does the course content cover modern orchestration tools like Kubernetes and service meshes?Yes, the professional and advanced tracks delve deeply into cloud-native infrastructure abstractions, container management ecosystems, and service mesh microservices architectures. These tools are evaluated through the lens of ensuring consistent service delivery and maintaining robust, redundant network routing frameworks.
- How does this certification directly impact my daily compensation and career trajectory?Holding this credential positions you for high-demand senior roles such as Platform Engineer, Infrastructure Architect, or SRE Lead. Organizations place premium valuations on professionals who can verifiably protect their uptime, leading to significant competitive advantages in global hiring markets.
- Can technical managers benefit from this program or is it strictly for hands-on engineers?Technical managers gain massive advantages by understanding these principles, as it equips them with the frameworks needed to structure teams, define objective performance goals, and manage engineering priorities without introducing friction between developers and operators.
- What specific automation methodologies are emphasized throughout the training tracks?The training emphasizes declarative infrastructure management, continuous deployment pipeline automation, self-healing runtime systems, and automated telemetry ingestion patterns. The goal is to systematically eliminate repetitive, manual operational tasks from an engineer’s daily workload.
- How should I structure my practical laboratory environment while preparing for the exam?Candidates should build local or cloud-based sandboxes using containers to simulate multi-tiered web architectures. Practice inducing simulated failures, configuring centralized telemetry dashboards, and writing specific automation mechanisms to resolve those issues without human intervention.
- What strategy does the program teach for managing high-severity production incidents effectively?The curriculum teaches structured incident command frameworks, clear communication protocols for stakeholders, automated triage isolation techniques, and fast rollback strategies. This structured approach ensures that teams remain calm, efficient, and methodical during critical platform outages.
- How does this certification address the challenges of handling legacy enterprise applications?It provides specific adaptation strategies for wrap-around monitoring, automated infrastructure translation layers, and incremental migration patterns. This ensures that legacy software stacks can be managed with the same reliability principles used for modern cloud-native systems.
Final Thoughts: Is Certified Site Reliability Engineer Worth It?
Investing in professional development requires a clear understanding of long-term career returns. The Certified Site Reliability Engineer path offers an authentic, engineering-first approach to solving modern infrastructure challenges. It avoids passing industry trends and focuses instead on core architectural truths and automation frameworks that remain valid regardless of specific vendor dominance. For engineers seeking to step into high-impact platform roles, this educational structure provides the necessary analytical tools and operational authority. It requires dedicated study and practical experimentation, but the resulting capability to design and maintain resilient, enterprise-scale platforms makes it an exceptionally grounded and valuable asset for your career progression.